
Christopher Prom and Kate Murray
For many of us, email comprises the journal of our personal and professional daily life. We use it to exchange quick notes and detailed information; we make plans for business meetings or casual lunches; we catch up with family, friends, and colleagues; we give opinions, make decisions, and discuss the news of the day. Even with the rise of other social media platforms and instant messaging applications, email remains in widespread use today with a solid future ahead. But perhaps more important for archives and libraries, email has a long history of adoption, and many collecting institutions receive material long after its creation date. Just like the bundles of letters in an attic, petabytes of email accounts are cueing up in professional and personal accounts. But will they ever pass through the virtual doors of archives around the world?
As the Mellon Foundation and the Digital Preservation Coalition-sponsored Task Force on Technical Approaches for Email Archives discovered over the course of its work, email is fundamentally a different beast than traditional paper-based personal papers and letters. The problems of email archiving arise from how contents are organized, or disorganized, before they are captured by archivists. In a nutshell, the complexity of email archives and the scope of attachment formats—combined with the sheer scale and volume of email collections, and the paucity of robust tool sets—make email archiving a potentially daunting task.
By assessing current efforts to preserve email, articulating a conceptual and technical framework, and constructing a community agenda for future work, the task force members developed a tiered set of recommendations focused on two complementary areas: (1) community development and advocacy, and (2) tool support, testing, and development. In The Future of Email Archives report released by CLIR this week, the task force lists suggested activities for each area. These include both low-barrier actions, which the community can start addressing immediately, and projects that require more planning and funding.
One of the most challenging issues from an archival perspective stems from email’s ubiquity: because it is so integrated with our daily life, email collections are ripe with personal, sensitive, and private information. Archivists and curators need powerful and flexible open-source tools to automatically identify, remove, redact, and restrict personally identifiable information (PII) or otherwise sensitive information—a process commonly known as sensitivity review.
The onus on the email archiving community is to build trust for both the donor and researcher communities through strong policies and actions with respect to accessioning, appraisal, and preservation, supported by scalable and cost-effective technologies that enable sensitivity review, redaction, and access. While search and discover functions exist for structured classes of PII such as Social Security numbers and phone numbers, this functionality does not extend to less-structured information such as education or health records. Also absent is reliable search functionality for less defined “fuzzy” searches that don’t rely on specific terms. Without these capabilities, donors are reluctant to include email collections in potential acquisitions, and historians and other researchers struggle to interact with the data in a meaningful way, if they can even get access to the data.
Cost effectiveness is the key concept here. Email archiving functionality already exists but it’s most active in proprietary software tools typically used by the legal community for eDiscovery and declassification services. It is out of reach for many on the archiving side. The challenge is two-pronged: (1) improve the tools, and (2) make them widely available through open source development and sustained management efforts.
On the “improve the tools” side, natural language processing (NLP) applications and machine-learning software could be enhanced to improve the ability of collections managers to identify and extract more nuanced entities from the archive. Current NLP workflows rely on named entity recognition to identify just certain data types, such as persons, corporations, and places, even offering some comparisons against specific categories in Wikipedia.
On the “more widely available” side, the goal is to open both the software code and access to the improved toolsets outside of closed or proprietary systems. Focusing on open source development would allow a transparent and adaptable development framework. But open source does not mean unstructured and unsupported.
All is not doom and gloom. The report demonstrates that all archives—from the smallest-staffed unit allied with a local history society to the largest academic or government archives—can take steps to preserve email. The key lies in defining a target storage format, then leveraging current tools and services to move email from its current storage locations into a repository infrastructure. Since mail transport and exchange operate via a standardized, well-known set of protocols, archivists can chain together tools to capture and process collections.
One of the most valuable sections of the report is the description of tools and workflows. These build on each other from simple to complex. Preserving the bit stream of messages in a format like PST—the proprietary but open format that Outlook uses to export messages—is a good first step. The following figure illustrates this process at work.
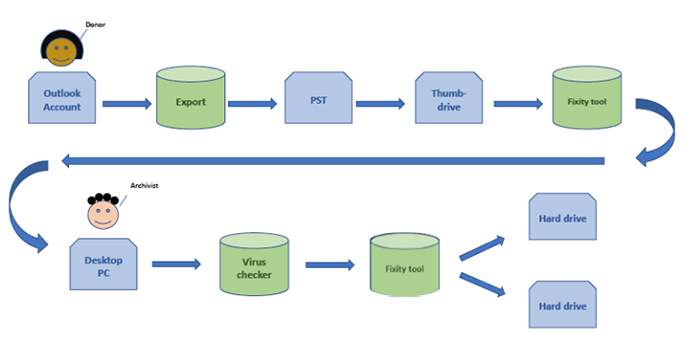
Processing email using this or a similar method (perhaps converting to a format like MBOX and saving attachments in their original binary formats) leaves open the possibility of applying more complex approaches later. The report provides many ideas and workflows to do just that, whether the repository’s goal is migration, emulation, or a combination of both.
Today, email is present in many of the most prominent news stories and is frequently cited in the latest exposés. But the first draft of history does not need to be the last word. And this brings us to perhaps the core takeaway from the task force’s work: archives and libraries are now primed for success in preserving email archives. Tools are maturing, but they just need a little boost. With some additional support, work, and community building, we can and will move toward greater interoperability and ease of use for all.
Christopher Prom is assistant university archivist and Andrew S. G. Turyn Professor at the University of Illinois at Urbana-Champaign. Kate Murray is Digital Projects Coordinator at the Library of Congress.