
[ contents ] [ previous ] [ next ]
I think that historians need a computer to document even more fully their research process and to allow others into that process. I believe we will move into a process of scholarly production and communication that is cumulative, discipline based, and verifiable in digital form. Beyond that I imagine that readers of history want to have access to materials that historians work with and interpret. The historians should use the computer to open up their work and make it more visible, relevant, and meaningful to the public.
-William G. Thomas, Railroads and the Making
of Modern America
3.1 Why Computers? What Kinds of New Research?
We have explored the common characteristics of the eight inaugural Digging into Data projects and hinted at some of their diversity and complexity, but what of their significance? What kinds of new discoveries in the humanities and social sciences have these investigators reported to date?34 What are the answers to this assessment’s initial questions: Why do you as a scholar need a computer to do your work? and What kinds of new research can be done when computer algorithms are applied to large data corpora?
One consistent metaphor in this study likens the computer to a moveable and adjustable lens that allows scholars to view their subjects more closely, more distantly, or from a different angle than would be possible without it. Daniel Cohen, a principal investigator for Data Mining with Criminal Intent, described two “use cases” for investigating the massive corpus of 197,000 digitized and coded trial transcripts within The Old Bailey Proceedings Online.35 The first, which he called “hunt and peck,” involves picking out a few examples of specific phenomena from within a vast data corpus; the second, which he called “slices,” is a way to look for trends and anomalies across larger amounts of data. In their white paper, the group cites examples of both types of use. By “hunting and pecking” for cases with references to “poison,” historian and developer Fred Gibbs discovered frequent co-occurrences of “poison,” “drank,” and “coffee,” suggesting to him that coffee was the poisoner’s medium of choice in eighteenth- and nineteenth-century London. By contrast, Tim Hitchcock and William Turkel have extracted vast “slices” from the Old Bailey corpus to create scatter plots of trial transcript lengths over time, as in Figure 2, which represents Old Bailey trials from the 1860s.
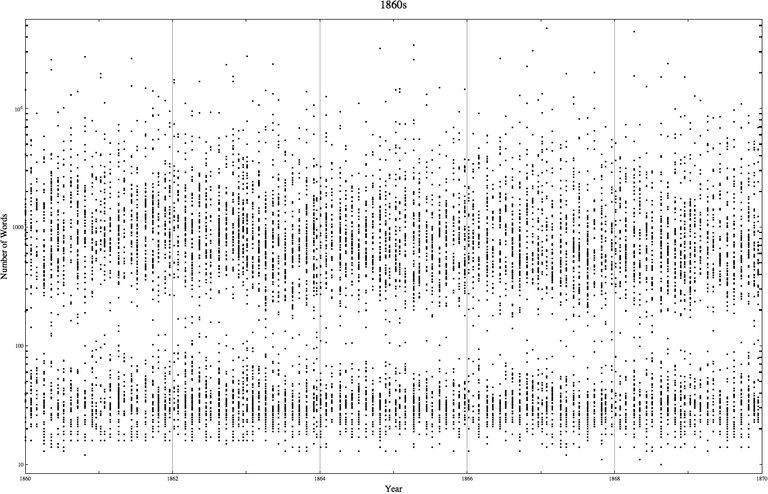
Fig. 2: Scatter plot created in Mathematica showing distribution of Old Bailey trial lengths in the 1860s, by Tim Hitchcock and William Turkel.
The results are intriguing: “As far as we know, no one has ever observed that the printed trials in this decade and a number of others were either shorter than about one hundred words, or considerably longer, but almost never around 100 words long. We are currently investigating the reason(s) why this may have been the case.”36
Project leaders indicated that perhaps the chief motivation of using these tools is that they allow scholars to ask questions that would not have occurred to them otherwise: this is the power of unexpected discovery that opens paths to new thinking and further questioning. Dan Edelstein and Paula Findlen emphasize this point in their white paper for Digging into the Enlightenment: their geographic visualizations of historic letters “can serve a heuristic purpose, leading the user toward less known corners of the dataset.”37 “We’re discovering research questions that we didn’t have when we started off,” echoed Peter Ainsworth, who led one of the teams on the Digging into Image Data project. Using an image segmentation algorithm developed during this project, Robert Markley and Michael Simeone were able to analyze digital images of 40 British and French historic maps of the Great Lakes dating from 1650 to 1800. Results showed marked inconsistencies between the depictions of some of the lakes’ borders over this period; they also showed that the mapmakers’ work did not become more “accurate” over time. Examining these inconsistencies, Simeone and Markley hypothesized that some “inaccuracies” reflected in the maps may actually correspond with water-level fluctuations and periods of prolonged ice cover. If they are able to collect more evidence to support this theory in their future research, Simeone and Markley “can begin to analyze maps prior to 1800 in order to provide usable data for historical climate models and future projections.”38
The promise for future revelatory explorations of our social and cultural heritage, explorations that should offer a more nuanced and expansive understanding of the human condition, is immense. The amount of work requisite to prepare and sustain the data for advanced research methodologies is nonetheless daunting. All the projects invested substantial time and effort in coaxing data corpora into reliable, “diggable” form, customizing analytical tools, or perfecting new, previously untested methodologies. The massive audio corpora at the heart of Mining a Year of Speech could be unlocked for investigation only after teams of researchers and students had used computer tools to align massive quantities of transcription with their corresponding audio data. Towards Dynamic Variorum Editions aspires to nothing less than the aggregation and morphological analysis of all extant works in classical languages; if the investigators reach this goal, they will have built the most powerful tool for philological inquiry in history. Yet for these scholars, much, much more remains to be done.
Railroads and the Making of Modern America provides a compelling case for the potential of computationally intensive research initiatives as well as for the need for painstaking care and effort in performing them. For this project, investigators Richard Healey and William G. Thomas integrated U.S. census and railroad company data to arrive at a more accurate estimate of the population of nineteenth-century railroad workers than had been previously offered by historians (Figure 3).
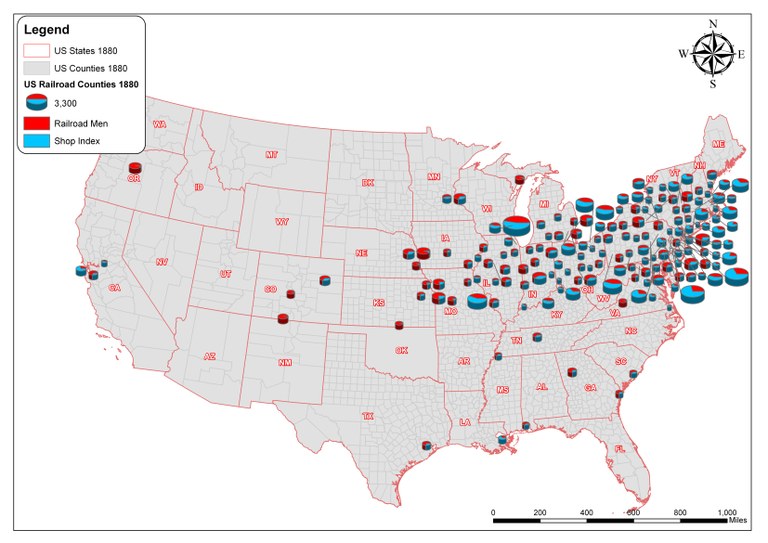
Fig.3: Integrated census (“Railroad Men”) and railroad company (“Shop Index”) data show the extent of railroad employment in the U.S. in 1880. Revealed are 38 “highly concentrated railroad centers.”39
By performing this data integration, Healey and Thomas showed that if historians take 1880 census data at face value, they miss the greater part of the railroad’s reach into the American workforce at that time. Only after working carefully with the data and investing significant time and hands-on effort could the scholars tell the full story.
3.2 Challenges and Concerns
Within the context of their day-to-day work, the challenges reported by investigators fell into four categories: funding issues, time issues, communication issues, and data issues.
Funding
• Funding is not always available in the amounts or for the resources most needed by investigators.
• Investigators need to continually seek external funding to sustain ongoing work.
• Many institutions lack long-term support for valuable project staff.
• Young scholars have difficulty getting travel support for meetings with collaborators.
• Computer storage infrastructure and processing cycles can be prohibitively expensive for humanists and social scientists working with large data sets.
Time
• Planning for and managing complex international, multidisciplinary collaborations takes extensive time.
• Data correction and tool development are time-consuming.
• Deep collaboration requires frequent synchronous communication, which is a major time commitment.
• Partners often have conflicting academic calendars and work schedules.
Communication
• Partners need patience and understanding to grasp perspectives of others from different backgrounds.
• Convincing technologists or computer scientists of the value of investing in humanities and social science work can be challenging.
• Managing expectations among partners with responsibilities for multiple projects can be tricky.
Data
• Data sharing requires shared tools and storage, and demands that partners trust one another.
• Making data “diggable” can be extremely labor-intensive. Error rates in data can be difficult to predict when planning a project and hard to account for in an analysis.
• Data management and analysis are iterative and cyclical, rather than sequential, activities.
The first of these categories, funding, is hardly surprising given these projects’ complexity and their demand for powerful computer resources as well as for diverse kinds of expertise. In all cases, the dollar and pound limits imposed by the grant program40 were not sufficient to achieve the researchers’ full ambitions. Accordingly, the investigators framed their projects around more modest goals. They noted both positive and negative consequences of the limits on funding. The need to secure support beyond what was available through Digging into Data was a frustration (albeit not an unfamiliar one). All eight projects leveraged significant resources from their institutions or other concurrent and related grants to fill gaps in their budgets. At the same time, many investigators observed that the smaller Challenge grants seemed appropriate for the risk-taking and experimental work they most wanted to do.
More of the researchers complained about the 15-month time limit for the grants, a challenge that was complicated for some teams when agency restrictions prevented the four cooperating funders from disbursing grant funds at the same time, resulting in some partners working to significantly different project calendars. In several cases, the compressed schedule made it difficult to hire qualified students for grant positions.
Communication challenges arose both from dealing with the inevitable pressures experienced in any collaboration among busy academics as well as from managing differing expectations. Working in geographically dispersed locations, some project teams coped with extreme time differences by managing communication asynchronously. While effective, this strategy slowed the process of making collective decisions and increased chances of misunderstandings and confusion. Unforeseen technical issues, as well as legal restrictions, prevented some collaborators from sharing data and software as quickly and openly as their partners hoped. Negotiating productive solutions to these problems sometimes cost precious time.
Data issues, as expected, were the thorniest of the challenges faced by investigators, though key differences between the projects surfaced, particularly the relative investment in manual manipulation versus automated “mining” and how each affected the results that were possible. Although the original emphasis of the Challenge was data analysis rather than management and organization, the experiences of investigators make clear that the two are deeply interdependent and that work in both is iterative and cyclical rather than sequential. This is particularly true for domains in which data are heterogeneous and unstructured. In these cases, manual intervention is often necessary. When the data themselves require significant scholarly effort, scholars often consider the resulting “clean” data to be just as important in potential impact as are the final research products the data make possible. As Richard Healey observed, “It has become clear that ‘making data diggable’ or providing ‘keys’ that unlock future digging potential may be just as important from a scholarly viewpoint, especially at this very early stage of the overall digging game.”
Investigators coping with error-riddled data, such as the imperfect OCR applied to the digitized newspapers consulted in the Railroads and the Making of Modern America project, had to spend more time than they anticipated coaxing files into a usable format. Those who benefited from highly structured data sets or dealt with more homogeneous data types, such as team members on the Data Mining with Criminal Intent or Digging into the Enlightenment projects, could spend more energy on developing tools for interrogation and analysis. In some projects, such as Mining a Year of Speech, it was difficult for investigators to predict what data issues might arise until their projects were under way. When coping with very large-scale corpora, accounting for the potential effects of erroneous data on scholarly interpretation becomes a significant challenge that is impossible to address manually.
Two perspectives on dealing with error:
Large scale implies that there will necessarily be many errors, even if the error rate is very low. Say 1% of words in a corpus are ”wrong” in some respect; e.g., wrongly annotated, classified, or indexed. 1% of a 100 million-word corpus is 1 million words with errors. Not only is it practically impossible to think of fixing 100% (even by crowd-sourcing etc.), one doesn’t even know where the errors are. The inevitable consequence, it seems to me, is that humanities research in the larger scale is going to have to accept and deal with errors in a statistical fashion, just as has always been commonplace in science.
-John Coleman, Mining a Year of Speech
One of the long-standing but often unwritten tenets of GIS [geographic information systems] work is that if you combine/integrate multiple data sources, all of which contain different types of errors, the resulting errors in the outputs can be multiplied many-fold, sometimes to the point where the results are effectively uninterpretable. So combining heterogeneous data sources can dramatically amplify error-related problems.
-Richard Healey, Railroads and the Making
of Modern America
The emergence of strong leadership, flexibility, and regular communication among the partners helped them resolve challenges as they arose. The partners working on Data Mining with Criminal Intent, for example, who brought together three relatively mature digital initiatives, attest that their weekly conference calls and frequent opportunities to meet face-to-face at scholarly conferences and workshops were key to their project’s success. All the Digging into Data investigators came to their projects as seasoned researchers with a great deal of experience of grant-funded work; none seemed to have found the challenges they experienced to be out of the ordinary.
3.3 Other Challenges: The Academic Culture
In conversations at the 2011 program conference, investigators identified other concerns they deemed much more critical than insufficient resources, time, or communication. The first concern was preserving their ability to receive fair credit for their individual contributions within a collaborative effort, particularly contributions to tool development and data curation. Complicating the issue is the open question of what kinds of contributions constitute “legitimate” research for a given discipline. The extensive work required to prepare data for investigation by computer tools, including various forms of data cleanup, the addition of metadata, format conversions, etc., is not, at least in some disciplines, considered “real” research, even though such activities often call for the expertise of advanced scholars. Software development, particularly in the humanities, is often seen as a service rather than as a core research activity. Striking a balance between preparatory, experimental, and interpretive research work was an ongoing challenge for the grant partners.
Other major concerns of the investigators included a lack of effective training opportunities, difficulties faced by students and junior scholars pursuing computationally intensive research, and a lack of suitable avenues for publishing data-rich media. Each of these is discussed below.
Overall, however, project participants expressed great satisfaction with the Digging into Data program, emphasizing that it created opportunities that would not otherwise have been possible, and that its groundbreaking mission and design gave a sense of significance and urgency to their work well beyond their previous experience with grant-funded projects. Many of the partners’ initiatives are expected to lead to other joint research efforts in the future.
3.4 Perspectives External to the Projects
In June 2011, participants in the Challenge convened at the National Endowment for the Humanities to present progress reports at a public symposium. Experts in each project domain contributed responses to these reports. After the symposium, the experts met with agency and CLIR representatives to discuss their impressions of the projects and their implications for the future of research. Their observations ranged widely, but many of them echoed the project participants’ self-assessments. The consensus conveyed at the meeting was positive, both in response to the program and to the individual projects. Key points that arose in this discussion include the following:
1. Level of investment: The experts stressed that the amounts of the Digging into Data awards were not sufficient to allow researchers to achieve their mid- to long-term research goals. They agreed that major institutional commitments, in addition to further incentives from funders, would be necessary to allow this kind of research to mature.
2. Refinements to tools developed for projects: The experts recognized that the tools used in the projects were among their most important deliverables. However, making these tools truly useful for other researchers, as most of the teams wish to do, will involve additional commitments that go beyond the original terms of the grants and the expertise levels represented among some of the teams. The experts suggested that institutions and agencies consider alternative programs for funding refinements to tools to make them broadly useful.
3. Methods and technical training:41 The experts noted that research methods and related technical training for computationally intensive research in some disciplines, such as linguistics, is currently much more sophisticated than in other disciplines, and that this seemed to affect the rigor of the analyses employed in some of the projects. In their view, some investigators seemed too distracted by the process of learning new technologies to select the best available solutions for their research problems. More critically, the experts noted that many graduate education programs in the subject domains represented among the projects do not provide sufficient training to equip younger scholars to lead future research initiatives of this kind. They recommended that institutions consider cross-disciplinary research methods training that would introduce both undergraduates and graduates to sound data management practices; to multiple modes of data analysis, including visual, geographical, and statistical; and to skills necessary for managing collaborations with scholarly and professional experts from multiple backgrounds and departments. They noted that future projects would need even stronger expertise in relevant technologies and research methodologies to achieve their potential.
4. Documentation and publication:42 Respondents noted an unfortunate incompatibility between the most important deliverables for these projects, including new tools, software, and data and their associated documentation, and peer-reviewed scholarly communication outlets available to researchers. They strongly recommended that institutions and agencies expand the range of outlets for scholars and broaden opportunities for earning credit for contributions that do not conform to traditional models for conference presentations, journal articles, and monographs. The lack of peer-reviewed publication alternatives is a significant disincentive for younger scholars to pursue computationally intensive research.43
5. Sustainability:44 Respondents expressed concern about the mid- to long-term sustainability of data and tools produced by these projects, and encouraged agencies and institutions to give this issue greater attention. They observed that the low level of participation in these kinds of projects at smaller institutions may reflect an inability of such institutions to offer support for incubating and sustaining these kinds of research. They noted that it would be impractical for investigators leading these projects to assume these burdens themselves. Further, they observed that outmoded assessment practices meant that younger, non-tenured scholars do not have sufficient incentives for contributing to established digital projects, embarking upon new digital research, or experimenting with new, computationally intensive modes of analysis, putting the long-term sustainability of digital projects at even greater risk.
6. Extensibility of methodologies: Respondents felt that most of the methodologies demonstrated in the projects were extensible beyond the domains in which they were developed, but they cautioned against seeing them as easily extensible. Expertise in research methods and modes of analysis will be necessary to adapt these methods successfully to new contexts.
3.5 Moving Forward
Digging into Data recipients made the following recommendations:
• Increase incentives for engaging in collaborative and multidisciplinary research, particularly for students and junior faculty.
• Establish standards for assessing collaborative and multidisciplinary work, including work on data and tools for exploration and analysis of data.
• Facilitate cross-disciplinary research tools and methods training for students, staff, and faculty.
• Support travel for those engaged in collaborative projects, particularly for students and junior faculty.
• Facilitate sharing of hardware, software, and data across institutions.
• Use licensing agreements and memoranda of understanding to clarify partners’ legal and ethical responsibilities on collaborative projects.
• Work toward multi-institutional strategies for data management that include long-term preservation.
• Increase the range of options for data-rich and multimedia scholarly publication across disciplines, particularly open-access publication.
The complexity of the Challenge projects, their diversity of approach, and the deep interdependency of their partnerships hold implications for the future-implications for the funding and staffing of academic departments, the training of academic professionals, and the education of students. The recipients of the first Digging into Data Challenge grants have offered suggestions in each of these areas.
When asked about how institutions of higher learning might better support computationally intensive research, investigators recommended increasing incentives to engage in collaborative and multidisciplinary projects, and establishing clearer, yet more flexible, standards for assessing such projects. They emphasized the need to cultivate the interest of undergraduates, graduate students, and junior faculty in participating in digital research. The involvement of graduate and undergraduate students in the Digging into Data projects was essential, most often through paid research internships and occasionally through coursework. Most investigators reported that their students found the work intellectually rewarding. As teaching faculty, the investigators were deeply committed to helping maintain this level of engagement throughout the project; they avoided relegating students solely to repetitive, low-level tasks and instead sought opportunities that offered the greatest creative challenges.
Among the more formal types of incentives mentioned by the investigators were cross-disciplinary internship or postdoctoral programs; multi-institutional, multidisciplinary, co-taught courses; and improved research methods, information architecture, and project management training for graduate students. Finally, while the assessment of digital scholarship has received increased attention in the past decade45 and many institutions have made progress in this area, the attitudes of the Digging into Data investigators suggested that assessment practices are changing much more slowly than they would like.
Increasing the number of opportunities for interaction among project partners, especially face-to-face meetings, was by far the most frequent suggestion made by project participants. Whether or not funds for travel had been included in their Digging into Data grants, most researchers found opportunities to meet at least once, and often several times, during the grant period. Participants credited these informal meetings with advancing their projects, building trust, and ensuring overall success. In addition to meeting face to face, many investigators credited frequent teleconferences or videoconferences among partners with project success. A past history of collaboration and, in two cases, the employment of a single individual by two of the partner institutions, strengthened communication and understanding among project stakeholders.
As for what higher education at the national and international levels might do, investigators echoed their strong support for broadening the range of peer-reviewed dissemination opportunities for humanities and social science researchers, including digital monographs, online conference proceedings that are edited or commented upon by conference participants, and online journals and data repositories. These should include affordances for embedding multimedia and interactive data visualizations within published work. New, stable, and secure collaborative research environments shared across institutions are also required to support this research.
Clearly this supporting cyberinfrastructure demands major, long-term investments. The ideal system will be multi-institutional, multidisciplinary, and distributed rather than centralized. Robust architecture of this kind will take careful planning and dedicated, professional maintenance-scholarly expertise in this area will be essential, yet relying on this expertise alone will not be enough. The Digging into Data researchers and their like-minded colleagues are deeply committed to advancing research in their disciplines, and understandably their priorities lie in the pursuit of new work rather than in the long-term preservation of their past and current research products. Even those scholars who are keenly interested in sustainability often lack the experience and training for planning research projects in ways that would enable repositories to accept their data or make it possible for other scholars to reuse those data in the context of other disciplines. Nevertheless, most researchers doing computationally intensive work recognize that their data should be stored long term, and stored in ways that are permanently linked to information about their provenance as well as to any future work that may rely upon them. In addition to data, algorithms, interfaces, and other tools used to explore data must be preserved and given proper context. Given these demands, it is clear that new models of publication will call for publishers, libraries, and other information suppliers and repositories to have a sophisticated understanding of evolving research practice as well as evolving technologies.
Some of the Digging into Data investigators emphasized that embracing open access, data sharing, and open-source software development would be critical to advancing research like theirs. While support for making open data a prerequisite of funding among Challenge grant recipients was not universal, there was considerable appetite for the agencies to encourage openness more forcefully.46 The Towards Dynamic Variorum Editions team argues persuasively for the benefits of openness for the public at large; they write, “We are able to develop intellectual conversations that can, if we so choose, serve to advance our understanding and to reach a wider audience-and to both at once without compromise.”47 As a practical means to this more inclusive, international academic culture, the Digging into Image Data partners advocate for the use of model partnership agreements such as memoranda of understanding that both protect researchers’ rights to credit for their work and establish rules for sharing hardware, software, data, and credit among partners. Other teams stressed that making data available through application programming interfaces is not sufficient for many purposes where the ability to manipulate data is critical; they noted that the corpora listed on the Digging into Data website48 seem to offer varying degrees of access to researchers.
While all Challenge respondents reported that their projects had met or exceeded their expectations, several factors seem to have enhanced their perceptions of success. Trust among partners, whether built formally through memoranda of understanding or informally through frequent communication about expectations and roles, was a major factor influencing these perceptions. Those working within more familiar collaborative partnerships in which they had already built bonds of trust generally found the planning and coordination of their projects easiest; for others, project management and communication required more formality and greater effort. Designing projects that provide mutual and equal benefits to partners was another important factor contributing to the satisfaction of participants: most projects set out to make significant impacts on multiple fields (i.e., computer science and humanities or social science). The Digging into Data teams stressed the importance of involving computer science faculty and students not in supportive or developers’ roles but as active research partners; given the limited level of funding available, the additional incentive of contributing to the advancement of computer science was seen as critical. From the perspective of the computer scientists and engineers on many of these teams, the complexity, ambiguity, and unstructured nature of humanities and social science data posed intellectual and creative challenges beyond those they had encountered on other projects.
In general, the researchers viewed their work as augmenting and transforming, rather than supplanting, research practice within their disciplines. The new methodologies they and others continue to develop will ultimately effect a much broader transformation: one that calls into question what the boundaries of those disciplines should ultimately be. It is time for international leaders and funders in higher education to take note of these changes and begin to adapt. There are exciting opportunities to incorporate computationally intensive research collaborations into curricula, staffing models, and professional development programs. This much is clear: “big data” are not just for scientists anymore. The new, bigger, and broader questions that computationally intensive research makes possible will not be simple to answer, and the tensions between the multiple, often oppositional, research traditions will not be easy to resolve. Yet we in the academy are becoming one culture. Whether we embrace and accommodate our differences is for us to decide.
FOOTNOTES
34 At time of writing, some of the Digging into Data projects funded in 2009 are still under way and have yet to report final results.
35 Tim Hitchcock, Robert Shoemaker, Clive Emsley, Sharon Howard, Jamie McLaughlin, et al., The Old Bailey Proceedings Online, 1674-1913 version 7.0, 24 March 2012. Available at http://www.oldbaileyonline.org.
36 Cohen, D., Hitchcock, T., Rockwell, G., et al. Data Mining with Criminal Intent. Final White Paper. August 31, 2011. Available at http://criminalintent.org/wp-content/uploads/sites/6/2011/09/Data-Mining-with-Criminal-Intent-Final1.pdf.
37 See page 7 of Edelstein’s and Findlen’s white paper for the NEH-funded portion of this project.
38 E-mail from Robert Markley to Christa Williford, June 14, 2011.
39 Thomas, William G., and Richard Healey. “Railroad Workers and Worker Mobility on the Great Plains,” Western History Association, Lake Tahoe, Nevada, October 2010.
40 The awards were limited to 100,000 US dollars (NEH, NSF), 100,000 Canadian dollars (SSHRC), and 100,000 British pounds (JISC).
41 Formal and informal education and training opportunities related to data-intensive research methodologies are growing more common worldwide, although formal training is still more common in the sciences (such as bioinformatics) than in the social sciences or humanities.
42 See, for example, the MediaCommons project (http://mediacommons.futureofthebook.org/about-mediacommons); Ball, A., and M. Duke, “Data Citation and Linking,” DCC Briefing Papers (Edinburgh: Digital Curation Centre, 2011), available at http://www.dcc.ac.uk/resources/briefing-papers/; Fitzpatrick, K. Planned Obsolescence: Publishing, Technology, and the Future of the Academy (New York: NYU Press, 2011); Withey, L., et al., “Sustaining Scholarly Publishing: New Business Models for University Presses” (2011); available at http://mediacommons.futureofthebook.org/mcpress/sustaining/.
43 The University of Florida George A. Smathers Libraries has created a “Facilitated Peer Review Committee” for establishing and testing models and means for assessment of non-traditional scholarly works. See: http://www.uflib.ufl.edu/committees/fprc/.
44 The academic library community has already taken up the challenge of supporting data-intensive research, but much work remains to be done to establish sustainable best practices for the management of research data that will work globally and across disciplines, at institutions both large and small. See Marcum, Deanna, and Gerald George, eds. The Data Deluge: Can Libraries Cope with E-Science? (Westport, CT: Greenwood Press, 2010).
45 See links collected at “Evaluating Digital Work for Tenure and Promotion: A Workshop for Evaluators and Candidates.” Modern Languages Association. Available at http://www.mla.org/resources/documents/rep_it/dig_eval.
46 In the second Digging into Data Challenge, the eight participating agencies have been advocating increased transparency in handling intellectual property–related issues. For example, JISC Director of the Strategic Content Alliance Stuart Dempster reports “paying site visits, forwarding exemplars of good practice and giving grantees a strong steer on licensing of project outputs” (e-mail to Brett Bobley, March 23, 2012). The JISC website has helpful information and tools related to intellectual property rights and licensing. See, for example, Naomi Korn, “Embedding Creative Commons Licenses into Digital Resources.” JISC Strategic Content Alliance Briefing Paper, 2011. Available at http://www.jisc.ac.uk/publications/programmerelated/2011/scaembeddingcclicencesbp.aspx.
47 See page 18 of the project white paper. See also Crane, G. “Give us Editors! Re-inventing the Edition and Re-thinking the Humanities.” In Online Humanities Scholarship: The Shape of Things to Come. (University of Virginia: Mellon Foundation, 2010). Available at http://cnx.org/content/m34316/latest/.