
[ contents ] [ previous ] [ next ]
by Lori M. Jahnke and Andrew Asher
We would like to thank the Alfred P. Sloan Foundation for its generous funding, which enabled us to carry out this study. Additional thanks goes to our many colleagues at CLIR who provided insightful commentary and support.
EXECUTIVE SUMMARY
CLIR was commissioned by the Alfred P. Sloan Foundation to complete a study of data curation practices among scholars at five institutions of higher education. We conducted ethnographic interviews with faculty, postdoctoral fellows, graduate students, and other researchers in a variety of social sciences disciplines. The goals of the study were to identify barriers to data curation, to recognize unmet researcher needs within the university environment, and to gain a holistic understanding of the workflows involved in the creation, management, and preservation of research data.
Key Findings
• None of the researchers interviewed for this study have received formal training in data management practices, nor do they express satisfaction with their level of expertise. Researchers are learning on the job in an ad hoc fashion.
• Few researchers, especially among those who are early in their career, think about long-term preservation of their data.
• The demands of publication output overwhelm long-term considerations of data curation. Metadata and documentation are of interest only if they help a researcher complete his or her work.
• There is a great need for more effective collaboration tools, as well as online spaces that support the volume of data generated and provide appropriate privacy and access controls.
• Few researchers are aware of the data services that the library might be able to provide and seem to regard the library as a dispensary of goods (e.g., books, articles) rather than a locus for real-time research/professional support.
Recommendations
• There is unlikely to be a single out-of-the-box solution that can be applied to the problem of data curation. Instead, an approach that emphasizes engagement with researchers and dialog around identifying or building the appropriate tools for a particular project is likely to be the most productive.
• Researchers must have access to adequate networked storage. Universities should consider revising their access policies to support multi-institutional research projects.
• Educational or other training programs should focus on early intervention in the researcher career path for the greatest long-term benefit.
• Data curation systems should be integrated with the active research phase (i.e., as a backup and collaboration solution).
• In the area of privacy and data access control, additional tools should be developed to manage confidential data and provide the necessary security. Most importantly, policies must be developed that support researchers in this use of these technologies.
• Many researchers expressed concerns surrounding the ethical re-use of research data. Additional work is needed to establish best practices in this area, particularly for qualitative data sets.
INTRODUCTION
By 1977 print media had already begun to show signs that its relevance was declining in relation to electronic media (Pool 1983). However, it was only after 2000 that digital storage formats became a significant portion of total storage media, and by 2007, 94 percent of technological memory was in digital format (Hilbert and López 2011). Although digital technologies have brought new opportunities for researchers to create data sets that enable increasingly sophisticated analyses, haphazard data management and preservation strategies endanger the benefits that this advancement might bring. Although digital data curation in its most basic form is merely saving the bits and bytes, the underlying ethical and philosophical issues related to sharing data amplify the technological challenge at hand. It is essential to address these issues in order to develop policies and infrastructure that truly support scholars in this new era.
The tasks associated with conducting research under a data-intensive paradigm increase the pressure on already overextended research schedules. Scholars are also grappling with the ethical and philosophical problems of data sharing in a vacuum of coherent policy support for data linking and release. The purpose of this study is to gather a more complete and researcher-centered understanding of the data usage, management, and preservation practices of university-level faculty, postdoctoral researchers, and staff researchers. Our goals were to identify barriers to data curation within the university environment, as well as to
• gain a holistic understanding of the workflows involved in the creation, management, and preservation of research data;
• identify unmet researcher needs within these processes; and
• use this information to make curricular, policy, and funding recommendations for data curation practices.
We conducted ethnographic interviews at five institutions with researchers from a variety of disciplines in the social sciences (table 1; see Appendix A for an overview of the data). The interviews focused on how the researchers collect and analyze data; how they manage, preserve, and archive these data; and what training they have had in data curation practices (Appendix B).
BACKGROUND
The rapid shift in the materiality of data has had tremendous consequences for researchers and their products. As Mathews and colleagues note, “Simple notions of access are substantially complicated by shifting boundaries between what is considered information versus material, person versus artifact, and private property versus the public domain” (2011, 725). These researchers are referring to the use of stem cell lines in research and the inherent ambiguity of navigating privacy and consent when the research materials are both human-made and derived from human individuals. Issues of privacy and consent are no less relevant to social scientists. As the lines around research materials continue to blur, so do disciplinary boundaries, thus necessitating careful discussion of data access and security. King observes:
[P]arts of the biological sciences are effectively becoming social sciences, as genomics, proteomics, metabolomics, and brain imaging produce large numbers of person level variables, and researchers in these fields join in the hunt for measures of behavioral phenotypes. In parallel, computer scientists and physicists are delving into social science data with their new methods and data-collection schemes (King 2011, 719).
The practical applications for integrating data from diverse yet complementary fields are numerous. For example, synthesizing social science, ecological, and hydrological data could help society cope with climate change (Overpeck et al. 2011), design better cities (Gur et al. 2011), and improve public health and the delivery of care. Standardizing and linking data from demographic studies, health surveillance systems, and pathogen-related studies could significantly improve the delivery of health care in remote areas that lack local medical expertise (Lang 2011).
Thoughtfully integrated pools of data could also promote transparency in research (Gur et al. 2011) and improve research methodologies by enabling the identification of unstated assumptions or theories that shape analytical outcomes (Rzhetsky et al. 2006; Smail 2008). Cokol and colleagues (2005) have demonstrated that in the sciences researchers tend to focus on established areas of knowledge rather than testing novel approaches and methods. As a result, popular fields may be overstudied while other lines of inquiry may be neglected entirely. Evans and Foster (2011) argue that a meta-analysis of research findings (i.e., publications) could identify overstudied fields where continued research has diminishing returns, thus helping individuals make better decisions about research investment. Aggregated research data could make such efficiencies clear. Failed investigations rarely receive the attention of a publication, but they do generate data that may indicate invalid approaches or the lack of merit in a particular line of inquiry. The aversion to publishing less than stellar outcomes leads to a tremendous duplication of scholarly effort.
Despite its advantages, integrating data from multiple fields is not without risk to the preservation of the intellectual rigor of academe. In the field of neuroscience, for example, Akil and colleagues (2011) suggest that integrating neural connectivity data with behavioral phenotype data (e.g., IQ scores) will provide new insight into the spatial organization and function of the human brain. This may be true. However, the validity of intelligence testing is a notoriously contentious topic, and the concept of intelligence is rather subjective (Nisbett 2003). Anthropologists and feminists, among others, have long disputed the validity of IQ tests, as well as the merit of characterizing psychological properties as human universals when the experiments frequently rely on American undergraduates as the research subjects.1 Henrich and colleagues (2010) have shown that the universality of undergraduate cognition is a false assumption. In fact, they conclude that WEIRD (Western Educated Industrialized Rich and Democratic) subjects are among the least representative populations for characterizing the fundamentals of human psychology. Without sufficient attention to the context of data aggregated from an array of fields, we run the risk of promoting facile interpretations of the relationship between human biology and behavior, and of human nature itself.
The form and quantity of information available could make possible significant advancement in addressing societal problems, if we can provide sustainable infrastructure and formulate the coherent policies needed to support it. The data deluge leaves us with several big questions; the answers will help define individual privacy rights, personhood, electronic identity, and our relationship to these concepts. We face a tremendous challenge in preserving the vast amounts of research data while balancing the need to protect sensitive data with the need to provide meaningful access for researchers and other stakeholders. This task cannot be accomplished without the investment of the researchers themselves.
| Site | Type* | Size* | Enrollment Classification* | Research Classification* | Disciplines/Areas of Study |
|---|---|---|---|---|---|
| Penn State University | Public | 45,185 | High undergraduate | Research university/very high activity | Biological Anthropology, Archaeology, Sociology Education, Slavic Languages |
| Lehigh University | Private, not-for-profit |
6,996 | High undergraduate | Research university/high activity | Psychology, Education, Political Science, Architectural History |
| Bucknell University | Private, not-for-profit |
3,737 | Very high undergraduate | Baccalaureate/arts and sciences | Political Science, Sociology, Environmental Science, International Relations, Anthropology |
| Johns Hopkins University | Private, not-for-profit |
20,383 | Majority graduate/professional | Research university/very high activity | Sociology and Public Policy, Applied Mathematics, Geology (data scientist), Sociology, Anthropology |
| University of Pennsylvania | Private, not-for-profit |
24,599 | Majority graduate/professional | Research university/very high activity | Education, Archaeology, History |
Table 1. Characteristics of research sites included in this study
* Information from Carnegie Foundation for the Advancement of Teaching (2010).
RESEARCHER PERSPECTIVES AND
UNMET NEEDS
Several studies have acknowledged that rates of coauthorship are increasing across academe and that the collaborative laboratory work model is replacing that of the lone scholar-genius (King 2011). Although there are certainly larger social and economic factors at work here, undoubtedly access to more data is changing not only the way that social scientists work, but also the kinds of questions that they can investigate. The incorporation of data from a variety of sources to address a single research problem causes the proliferation of roles within the research team without clear avenues of support and training.
Participants in this study included researchers in the social sciences of various ranks, but the focus was on early career professionals. We initially planned to interview postdoctoral fellows, junior rank faculty, and researchers exclusively, but it quickly became apparent that the challenges of digital data curation are spread widely throughout the scholarly workforce and that issues related to rank and training are interwoven with the complexities of multidisciplinary research teams. In the hope of providing a broader perspective on unmet needs in academe and changing needs over time, we also included a few advanced graduate students, as well as senior faculty (table 2).
| Participant # | Rank/title | Ph.D. Discipline |
|---|---|---|
| 1-03-100511 | Assistant Professor | Anthropology (Biological) |
| 1-17-121211 | Assistant Professor | Education |
| 2-12-111011 | Assistant Professor | Environmental Science |
| 2-16-120211 | Assistant Professor | Anthropology |
| 3-05-102111 | Assistant Professor | Developmental Psychology |
| 3-07-102111 | Assistant Professor | Political Science |
| 3-08-102111 | Assistant Professor | Political Science |
| 2-22-021512 | Professor | Environmental Studies |
| 2-15-120211 | Associate Professor | International Relations |
| 5-09-103111 | Data Scientist | Geology |
| 1-01-72911 | Digital Curator | Slavic Languages |
| 5-10-103111 | Graduate Student | Sociology |
| 5-20-020212 | Graduate Student | Environmental engineering |
| 5-21-02032011 | Graduate Student | Anthropology |
| 3-06-102111 | Grant Coordinator of a research center | Education |
| 1-04-100511 | Postdoctoral Fellow | Sociology (Demography) |
| 4-25-120511 | Postdoctoral Fellow | Education (Learning Sciences) |
| 3-14-113011 | Postdoctoral Fellow | Architectural history |
| 4-19-012012 | Postdoctoral Fellow | History |
| 2-13-111411 | Professor | Sociology |
| 5-11-103111 | Professor | Sociology |
| 1-02-100511 | Professor | Anthropology (Archaeology) |
| 4-18-121911 | Researcher | Anthropology (Archaeology) |
Table 2. Rank and academic discipline of the study participants
Participants expressed several different perspectives on the relationship of their data to the demands placed on them for scholarly production and teaching, as well as on their access to university services and appropriate training. None of the scholars interviewed during this study expressed satisfaction with their level of expertise in data management, and few had access to individuals who could provide knowledgeable guidance. On the contrary, most participants reported feeling adrift when establishing protocols for managing their data and added that they lacked the resources to determine best practices, let alone to implement them. Almost none of the scholars reported that data curation training was part of their graduate curriculum. Data management was typically discussed only in research methods courses and often only at a cursory level of detail in relation to methodological approaches and problems. The difficulties involved in the practical aspects of managing and preserving large amounts of research data were rarely addressed in these methods courses, and most researchers reported learning the necessary skills “on the job” via trial and error.
The transition to digital data collection has altered scholarly workflows. The greater ease of collecting data digitally has likely increased the amount of data collected, particularly with certain types of documentation, such as digital images. Researchers need no longer stretch a limited supplies budget to cover the high cost of film and, without this restriction, may be less judicious with their documentation. In the case of digital media, it is better to collect data than to regret and leave curation decisions to some abstract future date. Additionally, analog data collection requires a significant investment of effort in data entry prior to the analysis phase. Depending on the size of the project and the funding available, data may be double or triple entered by a series of undergraduate and graduate research assistants, or they may be outsourced to data entry professionals for the well funded projects. Collecting data digitally eliminates this labor investment and shortens the lag between observation and analysis.
Although digital data collection offers certain efficiencies in moving from the observation to the analysis phase, the associated data management tasks are not easily delegated. Efficient entry of analog data does not require any specialized skills beyond keyboarding accuracy, while effective digital data management requires both expertise and labor continuity that is not readily found in a pool of transient research assistants. Thus, an additional burden of labor has shifted to the scholars themselves, and they are grappling with ways to balance the changes in research labor with increasing expectations for teaching performance. The following sections summarize the most salient themes that emerged from the participant interviews.
Research Context and Workflow
Perhaps one of the more complicated issues for data curation is the complex life cycle of research data and the idiosyncratic growth of research projects. Rarely does data collection take place within a discrete phase of a project (figure 1). In fact, researchers may develop data protocols before the project is funded and may then change the protocols in response to issues as they arise.Collaborators may also join the project and contribute data that were collected under different circumstances. It may not be until the active research phase that data collection is systematic, although changes in protocol may occur even during this phase. In some cases, a project does not work out as planned, and researchers recycle it into a new research idea or take it in a new direction entirely.
Additionally, scholars may collect data on a phenomenon unrelated to their current project with no clear idea of the potential usefulness of those data. Such data might be integrated with a later project, given away to an interested colleague, or never used at all. For example, Participant #2-12-111011, Assistant Professor, Environmental Studies collected data on graffiti during fieldwork and then donated the data to another researcher (see Appendix C, case study #3). It is perhaps unrealistic to expect that research will follow a well defined, linear progression that can be neatly categorized. Importantly, because the researchers themselves could not always predict which data would be useful in the future (either for themselves or for other researchers), they were unsure which data should be preserved and what contextual information should be included with the data.
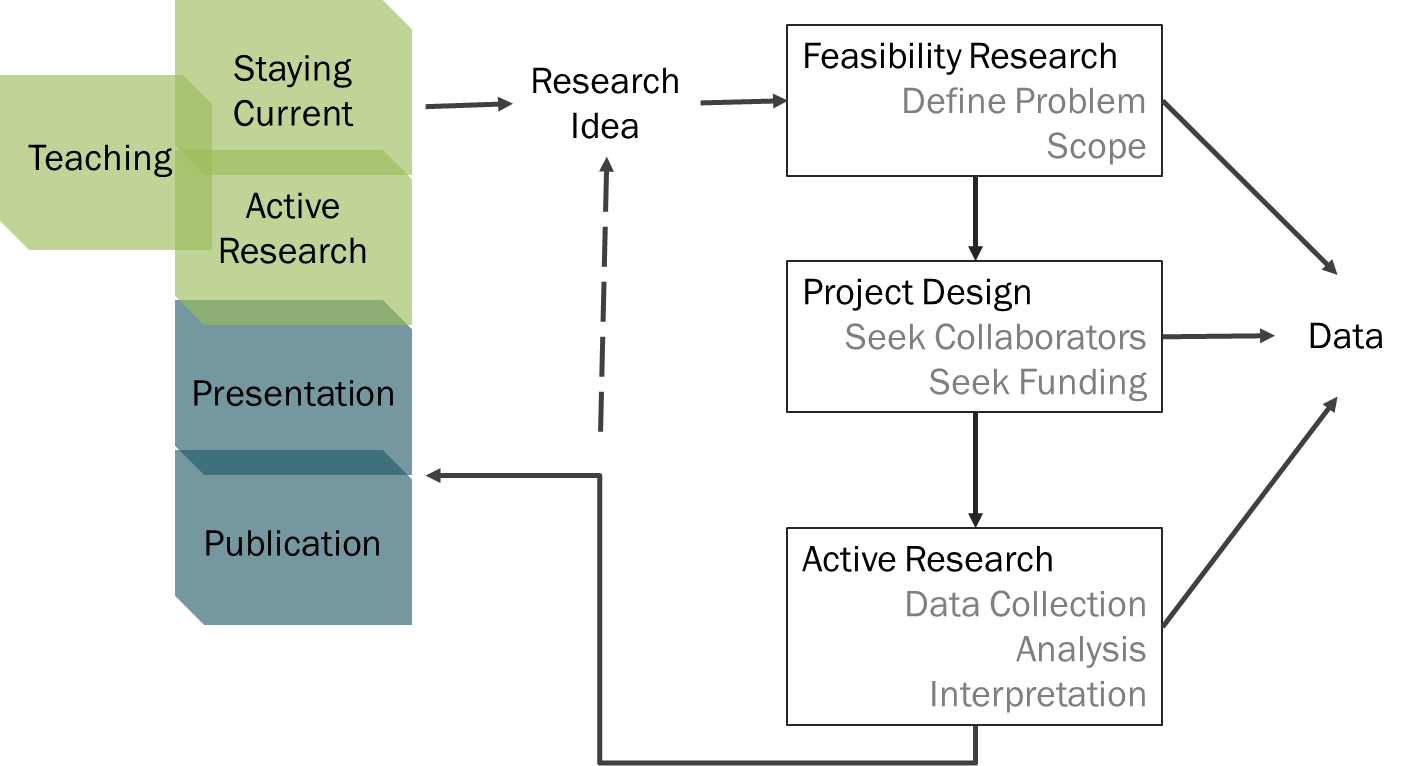
Fig. 1. Research workflow of a typical scholar showing the nonlinear development of research projects and the multiple stages at which data are collected
Several participants commented on the nonlinear nature of the research process and the way that this complicates data analysis and management. Participant #1-17-121211 described the nonlinearity of the research process as one of the most challenging aspects of working with data and noted the dynamic relationship between storage, analysis, and communicating results:
It would be nice if there was a way to collect data, have it migrate into a collection space, and in the collection space get it prepared for whatever analytics you’re going to engage in. And then have a place for the output of the analytics to go back into that collection space so that they’re connected in some way [with] your analysis and the data you’ve collected, which makes it easier to engage in the process of writing or making sense of this. Where you’re not simply looking at the results you also have access to the instruments that you used to collect and the questions that were related to those, as in the research questions, but also the instrument questions. Because those things have a way of finding their way into your. . . your write-up of the data or of your analysis but because of the sort of disparate and heterogeneous nature of it, becomes it’s like, you know, chasing cats (Participant #1-17-121211, Assistant Professor, Education).
This participant went on to describe tools that could remediate some of these difficulties, suggesting networked databases that include tools for ingesting data according to schema designed for the project’s research questions. Framing data ingestion with the research questions would facilitate linking the research findings to the analysis and observations. Cokol and colleagues (2005) discuss similar ideas for integrating research questions with data to improve analysis. The logistics of implementing such a system aside, this participant’s comments underscore the need for developing data management strategies early in the research process.
The researchers held contradictory views about the value of their data. Some study participants wondered who might be interested in their data while also expressing a desire to associate their data with publications or to have it available for use in the classroom (e.g., Participant #2-12-111011, Assistant Professor, Environmental Science). Other researchers wanted to create products other than research articles, such as websites, or to share certain aspects of the data, but they cited a lack of the skills or time needed to do so (Participant #3-06-102111, Grant Coordinator, Education).
Few of the researchers in this study thought about long-term preservation of their data, especially those who were early in their career. Perspectives regarding research data tend to be pragmatic. Given the nature of the academic system, which offers little or no career reward for preserving one’s data, this is not surprising. Typically, metadata and documentation are of interest to researchers only if it helps them complete their work and produce publications. After a project ends, the time required to add appropriate metadata often exceeds the researcher’s capacity and willingness to edit it, and the demands of publication output overwhelm long-term considerations of data curation. Many of the researchers were also skeptical of long-term interest in their data and were often doubtful that future researchers would be interested in their primary materials. This doubt contributes to scholars’ reluctance to allocate time to data preservation and annotation. Scholars are in great need of basic archival skills to help them set priorities for data curation tasks and decide which data should be preserved.
Overall, the researchers interviewed for this study exhibited an extremely wide range of data collection practices and habits, and they readily adapted research workflows to fit their current interests and needs. For this reason, file formats, as well as the software and hardware platforms used to manage and manipulate data, tend to proliferate. Data preservation strategies not only must take into account these varied, proprietary, and non-standard data formats, but also must provide a real-time benefit for the scholar in meeting research goals.
Collaboration and Data Sharing
Researchers need better online collaboration tools that provide more sophisticated access controls and can support the volume of data generated. Participants frequently reported exceeding their data quotas within university networks, and they sought tools that allow them to collaborate across institutions and manage data in a networked environment. Consequently, they routinely resorted to a constellation of personal computers, external hard drives, and commercial spaces, further compounding technical issues in data management. Several of the participants in this study were working on collaborative research projects that spanned multiple institutions (e.g., Participants #4-18-121911, #1-03-100511, #3-06-102111, and #1-17-121211), prompting project directors to seek non-university file-sharing options, such as Dropbox or Google Docs.
Using commercial “cloud” services as data storage locations poses potential privacy and security problems since the terms of service for these products are often poorly understood by researchers and the research participants. Furthermore, the terms of service may not be sufficient to meet the data protection and confidentiality standards that researchers and their institutional review boards (IRBs) require. Dropbox’s well publicized June 2011 security glitch, which left all Dropbox accounts open to access without a password for several hours, is indicative of this problem. Applying additional security measures, such as encrypting files locally prior to sharing them via a cloud service, is beyond the technical skills of many researchers, and it diminishes the ease of use that leads researchers to adopt these tools as a file-sharing solution. Universities’ common practice of limiting access to institutional networks to formally affiliated individuals has also contributed to this problem by making university-based systems of little use to multi-institutional collaborations. Universities should consider amending these policies to reflect the reality of multi-institutional research teams.
The field of physics offers a valuable lesson regarding the storage of data in personal accounts, as recounted by Curry (2011). From 1979 to 1986 a particle detector experiment called JADE (Japan, Deutschland, England) was performed at the PETRA e+e collider in Hamburg, Germany; the experiment resulted in several important discoveries for particle physics. In the more than 25 years since, theoretical insights and computing advancements have made the JADE data valuable once again. However, much of the data have been irrevocably lost to corrupt storage media, lost computer code, and deactivated personal accounts. These early particle physics experiments are unique, as modern colliders operate at higher energy levels and cannot replicate the particle interactions. Given the lack of infrastructure for sharing and storing data, the social sciences may face similar problems of data loss in documenting social phenomena as researchers begin to work within larger collaborative groups and with larger data sets. Data stored on personal media devices are especially vulnerable to this type of loss, as few scholars have the skills necessary to maintain data over time and across hardware and software platforms. Several of the scholars interviewed reported storing data on legacy systems that may become inaccessible (e.g., Participants #2-15-120211, #2-22-021512, #1-02-100511).
Although some researchers would welcome greater ease in sharing their data, particularly in collaborative projects, many are reluctant to enter into any arrangement in which they would relinquish control over access to the data. As one researcher described:
[P]eople don’t hesitate, at all, to share data with collaborators that they trust.… If you provide a mechanism for collaboration, even if it’s just Google Docs or something, you know, people share data easily and freely. It’s when it becomes an anonymous process that they seem to get balky (Participant #1-02-100511, Professor, Anthropology).
The willingness to share may be related to proximate goals in that easier data sharing facilitates collaboration within the project and reduces the proliferation of file versions, a routinely cited difficulty (e.g., Participants #2-16-120211, #1-17-121211, #3-06-102111).
Perspectives regarding data sharing beyond the research project are much more complex. Researchers have reported various ownership issues related to their data, and they are sensitive to the effects that releasing data might have on individuals related to the project (e.g., collections curators or study participants unintentionally identified). Researcher concerns related to protecting data privacy range from ensuring the physical safety of research participants (Participant #2-13-111411) to helping prevent the theft of objects from museums or other research locations (Participant #4-18-121911). Some researchers also report that ethical concerns about the appropriate use of their data underlie their desire to maintain control over who can access the data. Concerns regarding the misuse of data become particularly important in studies of marginalized groups of people and politically sensitive issues. Confidential and nonconfidential data are often intermingled in the data sets of social scientists, causing them to be inherently conservative about data sharing. In the following excerpt, a professor of sociology comments on the relationship of trends in social science data to the need for technological infrastructure that supports diligent privacy protection.
Sheer size can be a problem, but clearly the biggest problem is the problem of protection of privacy. The concern of privacy has been ramped up tremendously over the last 10 or 15 years, and the process of getting permission to analyze data can be difficult, but a trend in social science data is to include more and more information that’s sensitive. A lot of studies now include certain biomarkers and so a difficulty for us is providing secure facilities to do this, ‘cause frequently now a national survey organization will require very restrictive conditions. So, I’m also the director of something called the [name omitted], which is an organization that spans both campuses, has about 50 faculty associates, and we have a number of people who are analyzing this kind of data. And we have actually set up our own “cold room” at the School of Public Health, and we were looking forward to the library actually setting up a “cold room” or a “cool room” for us when the new [name omitted] commons building opens to accommodate this. While I have some resources as a professor to do some of this on my own, graduate students don’t that are working and in general, how to do this is a problem. I think the field is trying to now establish appropriate levels of protection for particular kinds of data and is trying to balance this problem of privacy with public access, and it is a challenge and it’s going to require some new modes of doing things. In one of our projects at the population center we’re partnering with ICPSR [Inter-university Consortium for Political and Social Research] to see if we can test distributed cold rooms where we would have a computer here at [university name omitted] that would have encoded communications, let’s say, with the computer at ICPSR so that we would never have the data here. So managing this kind of restricted access is difficult, especially for social scientists when they don’t have multimillion dollar grants. It’s becoming a bigger and bigger issue as the data gets better and better, i.e., has DNA markers in it (Participant #5-11-103111, Professor, Sociology).
The protective attitude toward research data might also lead (or even require) researchers to neglect metadata and secondary materials (e.g., codebooks, explanatory materials, finding aids, ontologies) that are necessary to ensure the long-term usefulness of primary data. If data are not to be disseminated, these aids are often unnecessary to individuals or small groups of researchers. Platforms that could provide both a workspace and a preservation space would add significant value for scholars. Additionally, university policies that appropriately address the ethical considerations relating to data sharing and preservation would benefit researchers, administrators, and technologists alike. These policies must go beyond the determination of who has access to which equipment to address the changing relationship of information to electronic identity and its influence on individual rights.
Training, Technical Issues, and Infrastructure
None of the researchers interviewed for this study had received formal training in data management practices. They were learning on the job in an ad hoc fashion. A few of the participants had consulted with experts in the field (e.g., Participant #5-09-103111 had consulted the Smithsonian Institution for guidance regarding the preservation of 16-bit color raw files) or had used self-help books and syllabi found online (Participants #1-04-100511 and #5-09-103111). By far, the most common strategy was to apply lessons learned in theory and methodology courses (e.g., statistics) and then learn by trial and error. The best-case scenario encountered during this study was a project at Penn State University that emphasizes ontology development at the beginning of the research process. Thus, graduate students and junior researchers received some training in data practices specific to that project while working within the lab or project team.
Few of the researchers interviewed for this study had developed a long-term data management plan for their research data. In the case of those who had developed a plan, the requirements of an outside funding agency, such as the National Science Foundation, were often the motivating factor. Nevertheless, the variety of audiences who might utilize the data (e.g., other scholars, policymakers, the public at large), as well as a lack of metadata standards for preserving information about a project, hindered researchers’ efforts to effectively share and disseminate their data.
The researchers are not naïve; they understand that poor data management can be costly to their research and that access to greater technical expertise, through either a consultant or additional training, would be useful for their work. However, it is unlikely that many researchers would undertake additional training. Participants in this study repeatedly cited a lack of time to conduct basic organizational tasks, let alone time to research best practices or participate in training sessions.
[S]o some organized system that is good for putting notes in but which you could easily attach files to would be good. Frankly, I’ve got so much stuff to do that I’m not likely to do that. Like I said, my guess is I could do that, my guess is you could attach, you could certainly attach links in a OneNote document, you might be able to attach the documents for all I know, but I also need someone to tell me that it’s in my interest to do it and kind of prod me and help me do it. Both urge me and help me to do it at the same time. ‘Cause otherwise, I’m not likely to archive stuff (Participant #5-11-103111, Professor, Sociology).
As with the creation of metadata, the economics of the scholarly reward system are likely to influence researcher perspectives on additional training (i.e., such training seems extraneous, as it does not directly contribute to publication production).
Researchers report that a variety of technical issues, such as inadequate access to networked storage, data loss because of poor organization, legacy file formats, and the scale of their data, can overwhelm available infrastructure. Although some of these issues stem from a lack of training or knowledge about best practices for data management, the issues cannot be separated from access to adequate infrastructure. As one researcher described:
[O]ne of the things that’s really helped us in the very recent past is being able to store all of our data or nearly all of our data on a server somewhere…. The infrastructure has to be there, I’m realizing now, in order to be able to even begin to organize yourself…it’s a combination of, sort of people and, and hardware that has to be there in order to facilitate someone like me who has a lot of data being able to manage those data effectively (Participant #1-03-100511, Assistant Professor, Anthropology).
The participant went on to describe a colleague’s more generously funded project that includes database programmers who manage large data sets of computed tomography (CT) scans. He emphasized the importance of having individuals who work closely with the project manage some of the technical aspects. This kind of support is beyond the means of most projects, leaving the researchers to manage data on their own. As another participant put it, “We really don’t have the level of expertise or the person dedicated to this that would bring, you know, the whole thing to fruition on the scale in which it’s envisioned” (Participant #4-18-121911, Researcher, Anthropology). As a result of this gap in technical expertise, parts of the project were scaled back or suspended indefinitely.
Researchers hold tremendous amounts of data on personal computers and hard drives, many of which are not backed up adequately. Among the participants in this study, the scale of research data ranged from under 1 GB to multiple terabytes. Data types included various formats of images, video, audio files, data sets (public and original), documents (paper and digital), code packages, and analysis scripts. Even individuals who are early in their research career may have amassed significant bodies of data (e.g., Participant #3-14-113011, a postdoctoral fellow, already had thousands of image files). Managing large files presents significant challenges for researchers in that university infrastructures typically do not provide adequate storage space or sufficient bandwidth for data access (e.g., Participant #4-25-120511 could not store videos from interviews with study participants on university servers). These data are vulnerable to loss when researchers upgrade their computers or software, and few researchers put more than minimal effort into organizing non-active data or ensuring its continued compatibility with new software or hardware.
Role of the Library
There is a clear need for libraries to move beyond passively providing technology to embrace the changes in scholarly production that emerging technologies have brought. Few researchers see the library as a partner, and most of the researchers in this study seemed to regard the library as a dispensary of goods (i.e., books, articles) rather than a locus for badly needed, real-time professional support. However, Participant #5-11-103111 characterized the library as an ideal location to create spaces for working with restricted data in compliance with governmental and other guidelines. These spaces would be particularly useful for graduate students and junior faculty who may not have their own labs. Furthermore, the creation of such spaces could facilitate researcher integration with data preservation programs.
FINDINGS AND RECOMMENDATIONS
The data preservation step must be fully integrated into a scholar’s research workflow. Not only are necessary metadata and other materials much more easily captured while research is in progress, but also there is a real opportunity to streamline research workflows and to provide much needed support. Scholars need help with the technical aspects of managing and preserving data, as well as with basic curation issues (e.g., what to keep and what to delete), and the ethical implications of sharing their data (e.g., what is an appropriate latency period for the data and how does one balance the need to provide meaningful access with the risk of inadvertently exposing confidential participant information).
Although some researchers acknowledge that their data could be useful to other researchers, there is little incentive to invest time in archiving or repackaging data sets. In fact, investing time in a project beyond its usefulness for publication is counterproductive, given the high expectations for producing research publications. In such cases, reframing data curation within a comprehensive backup and management strategy is potentially valuable; for example, it may be helpful to point out that data curation contributes to the success of the ongoing research program by alleviating many of the technical issues researchers face (e.g., data loss caused by poor organization, version issues, management of obsolete file formats for long-term projects, and provision of secure collaboration tools). Arguments aimed at convincing researchers to think about long-term data preservation for its own sake are not likely to be effective.
Our findings and recommendations are as follows:
1. An approach that emphasizes early engagement with researchers and dialog around finding/building the appropriate tools to manage data for a particular project/researcher is likely to be the most productive.
a. There is unlikely to be a single out-of-the-box solution that can be applied to the problem of data preservation.
b. Extensive outreach to scholars is necessary to build the relationships that will facilitate data preservation. This is likely to be a slow process initially.
c. Researchers are unlikely to engage with those they do not view as peers.
2. Researchers must have access to adequate networked storage.
a. Universities should not restrict access to infrastructure to individuals in permanent faculty positions.
b. Universities should revise their network policies to support multi-institutional research projects.
c. Researchers need additional tools to manage preserved data on their own, and they would benefit from access to professionals who can offer advice on management strategies.
3. Improved privacy and data access control are needed.
a. It is essential to develop tools that manage confidential data and provide the necessary security. Most importantly, policies must be developed that support researchers in the use of these technologies.
b. These systems must ensure that researchers have control over their data, as well as over who has access to it. Without such assurances, many researchers are unlikely to invest in these systems. In many cases, their desire to avoid the ethical risks of inappropriate data release may outweigh the costs of potential data loss.
4. Early intervention in the researcher career path is likely to have the greatest benefit.
a. Working with graduate students as they develop their first major research project is a key opportunity for education in best practices and the importance of good data management protocols.
b. Young scholars often have not considered the long-term value of their data or the importance of a systematic approach to data management. As their research develops and they begin teaching, they are likely to regret neglecting data management.
c. Small- to medium-sized research teams and single researchers are likely to have the greatest unmet need, because they typically lack the resources of major research initiatives to hire data professionals.
Researchers typically align themselves with their disciplines rather than with their institutions; therefore, support models that extend beyond the university are likely to be especially beneficial. Scholars also spend substantial periods of their careers migrating among institutions, particularly during the early phases. Researchers who are in temporary positions may not be willing to commit to a university data management system when they may leave in a year or two, and they may fear that they will be unable to retrieve their data at that time. Furthermore, research projects are frequently both interdisciplinary and interinstitutional. Thus, systems that restrict access to institutional affiliates would preclude multi-institutional collaboration among scholars in data sharing and preservation.
Reaching the level of collaboration among universities and the technical interoperability required to capture and preserve a career’s worth of data in the current environment is a challenge. A practical model for fostering both collaboration and interoperability may be a network of local data specialists who are aligned with disciplines and/or affiliated with a regional or national scholarly organization. A local data specialist who operates within the university to collaborate with researchers and who participates in a network that extends beyond the university would facilitate long-term collaboration with researchers as they move through the various stages of their career. Such a network would also provide the communication necessary to foster interoperability in technical solutions.
Our interviews with researchers suggest that data specialists should have at least some expertise—preferably considerable knowledge—in the discipline with which they are working. In the best-case scenario, a data specialist would be fully integrated into a research team and would also conduct research. These specialists are likely to need significant technical training in addition to their subject knowledge. However, given the variation of research modalities and the types of data generated, it is difficult to ascertain what type of technical training they will need until they are on the job. An iterative approach to training that builds on core technical skills and emphasizes identification of needs specific to subject or methodological areas may be effective.
Finally, it is likely that a data specialist will need to function as an advocate for researchers within the local systems. Although some universities already provide technological or other support that would be useful for researchers, the bureaucracy surrounding this support can severely limit researcher access. Scholars may not have the time or knowledge necessary to influence the policies that affect them. Furthermore, researchers of junior rank may not have sufficient influence to affect relevant policies. Thus, some basic training in policy development, negotiation, and academic administration may be useful for data specialists.
CONCLUSION
Current data management systems must be fundamentally improved so that they can meet the capacity demand for secure storage and transmission of research data. Integrating the data preservation system with the active research cycle is essential to encourage researcher investment. Enhancing the system with intuitive live linking visualization tools could add significant value for preliminary analyses (Fox and Hendler 2011), as well as curatorial decision-making.
There is also a clear need for “privacy enhanced protocols” (both policy and technical) that address the ethical concerns of researchers while creating standards for data latency, access, and attribution (Altman and King 2007; King 2011; Lawrence, Jones, and Matthews 2011). Researchers are not well positioned to meet the technical and policy challenges without the coordinated support of libraries, information technology units, and professionals who possess both technical and research expertise.
REFERENCES
Akil, Huda, Maryann E. Martone, and David C. Van Essen. 2011. Challenges and Opportunities in Mining Neuroscience Data. Science 331(6018): 708–712.
Altman, Micah, and Gary King. 2007. A Proposed Standard for the Scholarly Citation of Quantitative Data. D-lib Magazine 13(3/4): 1–13.
Arnett, Jeffrey J. 2008. The Neglected 95%: Why American Psychology Needs to Become Less American. The American Psychologist 63(7): 602-614.
Carnegie Foundation for the Advancement of Teaching. 2010. Carnegie Classification of Institutions of Higher Education. Available at http://classifications.carnegiefoundation.org/.
Cokol, Murat, Ivan Iossifov, Chani Weinreb, and Andrey Rzhetsky. 2005. Emergent Behavior of Growing Knowledge About Molecular Interactions. Nature Biotechnology 23(10): 1243–1247.
Curry, Andrew. 2011. Rescue of Old Data Offers Lesson for Particle Physicists. Science 331(6018): 694.
Evans, James A., and Jacob G. Foster. 2011. Metaknowledge. Science 331(6018): 721–725.
Fox, Peter, and James Hendler. 2011. Changing the Equation on Scientific Data Visualization. Science 331(6018): 705–708.
Gur, Ruben C., Farzin Irani, Sarah Seligman, et al. 2011. Challenges and Opportunities for Genomic Developmental Neuropsychology: Examples from the Penn-Drexel Collaborative Battery. The Clinical Neuropsychologist 25(6): 1029–1041.
Harris, Mark. 2007. Ways of Knowing: Anthropological Approaches to Crafting Experience and Knowledge. Brooklyn, NY: Berghahn Books.
Henrich, Joseph, Steven J. Heine, and Ara Norenzayan. 2010. The Weirdest People in the World? The Behavioral and Brain Sciences 33(2-3): 61–83; discussion 83–135.
Hilbert, Martin, and Priscila López. 2011. The World’s Technological Capacity to Store, Communicate, and Compute Information. Science 332(6025): 60-65.
King, Gary. 2011. Ensuring the Data-rich Future of the Social Sciences. Science 331(6018): 719–721.
Lang, Trudie. 2011. Advancing Global Health Research Through Digital Technology and Sharing Data. Science 331(6018): 714–717.
Lawrence, Bryan, Catherine Jones, and Brian Matthews. 2011. Citation and Peer Review of Data: Moving Towards Formal Data Publication. The International Journal of Digital Curation 6(2): 4–37.
Mathews, Debra J. H., Gregory D. Graff, Krishanu Saha, and David E. Winickoff. 2011. Access to Stem Cells and Data: Persons, Property Rights, and Scientific Progress. Science 331(6018): 725–727.
Nisbett, Richard E. 2003. The Geography of Thought: How Asians and Westerners Think Differently—and Why. New York: Free Press.
Overpeck, Jonathan T., Gerald A. Meehl, Sandrine Bony, and David R. Easterling. 2011. Climate Data Challenges in the 21st Century. Science 331(6018): 700–702.
Pool, Ithiel de Sola. 1983. Tracking the Flow of Information. Science 221(4611): 609–613.
Rzhetsky, Andrey, Ivan Iossifov, Ji Meng Loh, and Kevin P. White. 2006. Microparadigms: Chains of Collective Reasoning in Publications About Molecular Interactions. Proceedings of the National Academy of Sciences of the United States of America 103(13): 4940–4945.
Smail, Daniel Lord. 2008. On Deep History and the Brain. Berkeley and Los Angeles: University of California Press.
Appendix A: Data Overview
Research Activities/Example Projects
• Imaging of primate bone morphology and walking behavior in juvenile humans
• Girls’ expectations and transition to adulthood
• Cognitive development in children, using eye tracking equipment
• Behavioral diagnostics for educational programs and support for special needs program students
• Criminal justice policy analysis
• Reanalysis of archeological excavation site data
• Secondary analysis of literature
• Learning among children within an online environment
• Environmental issues and political protest in Kyrgyzstan
• Community-based nongovernmental organizations and civil society in Ethiopia
• Architectural history and landscape (Europe)
• Decision-making among Indian prime ministers: The policymaking process
• Effect of notebook computers on foreign language teachers
• Indian legal history and the British Empire
• Transformation of the welfare system in Turkey and the relationship to grassroots politics
• Changes in U.S. welfare policy, 1990–2006 (multisite study of 2,500 low-income families)
• Archaeological tourism in Highland Bolivia, 2002–2004
• Mummy bundles, Peru (historical archeological research), Database integrating data (between institutions)
• Development of a prototype for digital curation microservices (tools/applications driven by services, e.g., ingest of object/authenticating object, version control)
• Data curation for Antarctica McMurdo Dry Valleys (18 years of data): Documenting the magmatic plumbing system
• Antiterror laws in Turkey, prosecution of the Kurdish minority
• Archeology in the Gordian region, Turkey (and collaboration with civil rights nongovernmental organization)
Reported Issues
Collaboration
• Management of workflow across multiple campuses
• Inadequate online collaboration space
• Inadequate tools to manage versioning, etc.
Infrastructure
• Systems and infrastructure overwhelmed by scale of data
• Policy (e.g., varying levels of access complicate workflows for research teams that include undergraduate and graduate students)
Data loss
• Parts of personal archives lost (e.g., computer crash, organizational mistakes)
• Inadequate time and skill to maintain data in legacy file formats (e.g., MS Word)
Data sharing
• Lack of systems to adequately segregate and maintain control over sensitive data
• Some data considered proprietary by collection holders (museum collections)
• Philosophical perspectives on data sharing (e.g., ethical considerations, methodological complexities)
• Lack of suitable mechanisms for sharing
Training, support, and personal organization
• Little or no training, learning as needed throughout research
• No contact with university data services
• No archival planning
• Very limited backup procedures
• Difficulty maintaining and tracking support materials
• Unclear about need for (and definition of) metadata
• Unsure of best practices regarding preservation in terms of file formats
• Difficulty deciding what should be preserved and what should be destroyed
• Difficulty maintaining organizational structure of files, insufficient time for organizational tasks
Common Data Types
• Images: TIFF, raw, JPEG, KML (for display of geographic data)
• Video: mp4, mov
• Audio: wav, mp3, analog tape
• Data files: Excel, SPSS, STATA, ArcGIS, txt, various public data sets
• Documents: MS Word, PDF
• Paper-based: Manuscripts, newspapers, site reports, transcripts, field notes (often handwritten notebooks, sometimes scanned, but rarely transcribed), drawings/sketches, chemical analysis results, photographs
• Other: Code packages and documentation, tool prototypes, objects (artifacts/samples), Matlab scripts (e.g., Participant # 3-05-102111 uses Matlab scripts to transform txt files for analysis in SPSS)
Analytical Tools
• Google Earth
• ArcGIS
• ProfilesPlus (specialized software for policy analysis)
• Excel
• SPSS
• STATA
• Matlab
• Atlas.ti
• Qualtrics
• NVivo,
• Filemaker Pro
• MS Access
Management Tools
• File structure on personal computer and naming conventions
• Excel
• E-mail
• Website
• OneNote
Data Storage
The volume of data varies from a few gigabytes or smaller to multiple terabytes. Researchers report storing data in a variety of locations, including:
• University server system (RAID)
• Inter-university Consortium for Political and Social Research (ICPSR) archive (Participant #5-11-103111)
• SharePoint
• Personal computers (usually multiple)
• Work computers
• External hard drive
• “Cloud” storage (e.g., Google Docs, Dropbox)
• DVD
• Office (for physical materials)
Study participants are using a variety of locations to store data and are employing many combinations of the various locations. In some cases, they are using multiple locations because the capacity of any one location is insufficient to support the volume of data while enabling access from multiple locations (e.g., terabyte scale data of Participant #1-03-100511). In other cases, the dispersal of data reflects idiosyncratic work habits with insufficient time for organizational tasks.
Collaboration Tools
• File sharing software: Dropbox, Google Docs, SharePoint
• Database programs: Bento by Filemaker Pro, MS Access, Filemaker
• Communication and record keeping: Wikis (university and non-university), e-mail (university and non-university), Skype, other conference calling
• Hardware: University network, networked drives (within the lab), flash drives
• Outsourcing to a data support company
Collaboration Problems
• Versioning issues
• Volume of data too large for university networks (e.g., Participant #1-03-100511 had to mail a hard drive)
• Uneven access to university infrastructure (e.g., Participant #4-25-120511 reported that undergraduates and graduate students on a project do not have the same privileges as senior project members for network storage)
Appendix B: Interview Questions
Demographics:
• What is your academic discipline?
• What is your position?
• When did you complete your highest academic degree?
• Did your graduate program include training in curating or managing data?
• How would you define digital curation?
Background:
• Ask the participant to describe a research project she/he is currently working on (or recently completed). Ask the participant to narrate the process of completing the work from beginning to end.
• What were the goals of this project?
• How did you become involved in this project?
• What kind of data sources did you use in this project?
• What kinds of primary sources did you use?
• What kinds of secondary sources did you use?
• How did you locate these data sources?
• Did this project have a data preservation or a data management plan requirement?
Data Creation/Analysis:
• Did you create new data sources as part of this research (e.g., experimental results, data sets, coding files, indexes)? What kind?
• When/how were these data collected? Is data collection still active? If so, when do you expect it to be completed?
• What are the formats of the data used in this project?
• How many items are contained in the data set?
• How large are the files?
• How did you organize the data?
• How are the data named/numbered, etc.?
• Did you document this system?
• Are the data backed up? How/Where?
• How do you work with/analyze/manipulate/transform the data?
• What tools do you use? What formats do you work with?
• What problems have you encountered while working with the data?
• What are the products/outcomes of your work?
Collaboration:
• Do you collaborate with other researchers on this project?
• How do you manage this collaboration?
• How did you manage version control?
• What software (if any) did you use?
• If you wanted to go back and work with the data again, what would be the most important information to have?
• If someone wanted to replicate/reconstruct your analysis, what information would be needed?
Preservation:
• Once you were finished with this project, what happened to your research materials/data?
• Where are they located? In what format?
• Did anyone offer guidance in making these decisions?
• Do you have a plan/strategy for archiving these materials?
• Where will they be held?
• Who is responsible for them?
• (If not) Why don’t you archive your materials?
• What concerns do you have about archiving or curating your data?
• If someone were to return to your data in 5 to 10 years (or longer), what contextual information would be needed?
• If you were archiving your research for future scholars, what would be the most important things to be preserved?
• Who would potentially re-use this data?
• What are your expectations for this re-use (e.g., citation, copies of papers, reciprocity)?
• Do your data contain confidential and/or proprietary information (e.g., personally identifiable information, patentable information)?
• Would you publish your original data if you believed there was a suitable venue?
• What concerns do you have regarding publication methods?
• What are the most important factors when deciding if data are suitable for publication?
• Does your university or library offer any services to help you with curating your data?
• If the university (or library) were to offer services to help you with data curation, what would be the most helpful things they could provide?
Personal Practices and Training:
• Do you keep a personal archive of materials related to your scholarship (e.g., field notes, lab books, e-mails, photographs)?
• What formats are these materials in?
• How/Where are they stored?
• Have you had training in data curation?
• If so, what kind/what tools?
• Who provided the training?
• Do you feel that it was adequate?
• What would you like to know more about?
• During what phase of your research development did you receive this training?
• Did the timing seem appropriate for your work?
• How did the training influence the way you conducted your research?
For individuals fulfilling the role of digital curator:
• Do you conduct outreach as part of your curator responsibilities? If not, does another staff member fulfill this role?
• Who is the primary audience for outreach?
• Have the efforts been successful in engaging faculty or other stakeholders?
• What would you change about this process?
Appendix C: Case Studies
Case Study #1: Data Curation for the Antarctica McMurdo Dry Valleys Project
Participant #5-09-103111 was the only scholar interviewed during this study who was working in a position that was formally designated as a digital curator (in this case, a “data scientist”). Nevertheless, this researcher had no formal training in data curation except for his attendance at a summer institute at the University of Illinois. However, the researcher holds a master’s degree in both computer science and geology, giving him the combination of technical skills and deep disciplinary knowledge that is necessary for managing the data of the complex project he described.
This scholar’s project is the digital preservation and curation of approximately 18 years of research materials and geologic data collected in the McMurdo Dry Valleys of Antarctica. The data are diverse, including both physical and digital artifacts, and his tenure has spanned the migration of data collection from analog to “born digital” formats. At the outset of the project, the data curator made a detailed catalog of all data in need of preservation and noted the difficulty of archiving the materials in an electronic form. The materials to be archived include researchers’ field notes, personal journals of field seasons, chemical analyses, maps and aerial photographs, photographs (about 4,500 35-mm slides, as well as other images in a range of digital formats), geologic samples, thin sections (cut sections of rock mounted on glass slides to be viewed via microscope), and video of fluid dynamics experiments.
The goal of this project was to preserve and present as much of the material online as possible, and several types of materials presented particular difficulties. Analog 35-mm slides had to be converted to digital formats using a specialized Nikon slide scanner (Coolscan 5000; 16-bit color). The data curator consulted with the Smithsonian Institution for format preservation guidance and decided on an uncompressed TIFF format at the highest resolution available for long-tem preservation and JPEG files at lower resolution for presentation purposes. Associating sufficient metadata (including location and date) with photographs was often problematic, as the research team had included little or no metadata with the original photographs; some important photographs require time-consuming annotation by the original researcher. Excel spreadsheets were used to track the necessary metadata for the image files.
Physical objects have also proved difficult to present online. To obtain high-quality images of the geologic rock samples (more than 800), it was necessary to contract with a professional photographer. The thin sections also posed difficulties, because the images needed enough resolution to allow researchers to measure 200–500 grains of the mineral. Pixilation on lower resolution images renders them unusable, making very large files (up to 60–65 GB per section) necessary. These files not only create storage problems, since up to 100–150 TB are needed for the project, but also require specialized software tools to make the images usable online.
This project is currently in progress, and the team envisions a wide range of potential audiences for the curated materials, including other researchers, the general public, and primary and secondary students. The digital curator said that while the data have been prepared thus far principally for other researchers and therefore require an understanding of geological fieldwork to be meaningful, he envisions an “interactive geologic map” that would be useful to a wide audience.
Case Study #2: Walking Behavior in Juvenile Humans
Participant #1-03-100511 is a biological anthropologist who studies primate evolution and primate bone morphology using image data (high-resolution computed tomography). He is presently an assistant professor (doctorate completed in 2001) and had no digital curation or data management training as part of his graduate training. This scholar’s current project is a National Science Foundation (NSF)–funded, multi-institutional study of bone development and its relationship to the walking behavior of juvenile humans.
Data for this project are initially collected in an imaging lab and then processed locally in the researcher’s anthropology lab. Digital image files are transferred from an acquisition computer to a server, where they are maintained and backed up. The workflow for processing the bone images for analysis is complex and requires multiple specialized software programs for three-dimensional visualization and measurement. There are several thousand TIFF images for a single bone, and images are repositioned, sampled, and extracted to a Digital Imaging and Communications in Medicine (DICOM) format so that measurements can be made. The numerical data are analyzed in SPSS and Excel.
Tracking metadata for the images as they pass through the multiple processing steps has proved difficult. The initial bone imaging data include XML files with the metadata describing the scanner settings. The researchers wrote a custom PERL script to extract the metadata required for analysis as a text file, which is then imported into an Excel spreadsheet for tracking purposes. The researcher organizes and manages project data using a Windows file structure. However, metadata are not always held at every level of the file structure, and the members of the research team must consult the tracking spreadsheet, which sometimes creates confusion.
The need to share files among researchers at multiple universities has also created problems. FTP sites and university server solutions failed for technical reasons, requiring the researchers to mail a hard drive to members of the research team at another university. Tracking and metadata files have been shared via Dropbox, which initially created conflicting copies of documents and required the design of new workflows to avoid duplication.
Although this project has both an NSF data management plan and a physical anthropology data-sharing plan (a standard in physical anthropology for a number of years), several factors limit the effective reuse of the project’s research data. The ultimate goal for this project is to maintain all data sets indefinitely and potentially to make these data available for download via a website. However, no database is currently in place to make this possible, and the volume of materials (terabyte scale) makes preparing a database and the necessary metadata time-consuming; scanner settings must be described to reproduce the researcher’s methodology.
Bone collections often have tight restrictions on their use and reuse. For example, when the project needed chimpanzee bones to use for comparison with human bones, the researchers could not obtain samples locally. Thus, the researcher had to travel to Belgium to use a collection there, resulting in scans made on different types of equipment that required different processing steps. In addition, collection owners (e.g., museums) may consider bone scans proprietary, and they may assert ownership over data produced from their collections, limiting the sharing of data. In this case, data rights can become a source of conflict, as the researcher’s institution asserts ownership over data produced by university-owned scanners. These conflicts over data ownership and rights effectively render data unusable for other researchers and can lead data managers to be very conservative in their sharing processing and practices.
Case Study #3: Environmental Issues and Political Protest in Kyrgyzstan
Participant #2-12-111011 is an assistant professor of environmental science who studies environmental politics and protests in Kyrgyzstan.
This scholar collects quantitative and qualitative data using face-to-face interviews, as well as secondary data sets. She holds interview data on paper questionnaire forms, as well as in audio recordings. Quantitative results are stored in Excel and SPSS files, while the audio recordings are in the process of being transcribed. The researcher hopes to scan the print versions of her questionnaire forms and destroy the originals, which are presently stored in boxes in her office. Because she works in three languages (Kyrgyz, Russian, and English), the researcher has had difficulties hiring and training transcriptionists, and the transcription of her interviews has taken several years to complete. Transcription files have been managed by means of flash drives and Google Docs.
The researcher is concerned about her skills in data management. Although she has significant experience working with secondary data sets, she has had no formal training in data curation. In particular, she observed that she has a weak and nonsystematic backup plan for her data, relying principally on multiple personal computers and external hard drives. The organization of digital files is also very difficult for this researcher, and she finds the file management tools that are part of a computer’s operating system insufficient for her needs.
None of this researcher’s funding agencies have required a data-sharing or data management plan. However, she has a vague plan for preserving and making public her data, and she hopes to make some of her data available for use by other scholars and policymakers, particularly the quantitative data sets that she has used to conduct spatial analysis in geographic information systems (GIS). She is also interested in the potential for making public her qualitative interview results and notes, but has concerns about confidentiality and privacy. The researcher hopes to maintain her materials indefinitely for her own use—preferably on a university server (she is presently doing this for her GIS data).
This researcher’s experience demonstrates the unexpected and unpredictable uses of data sets. A graduate student working on graffiti images following an ethnic conflict in Kyrgyzstan asked the researcher for permission to use copies of photographs that the researcher had taken and cataloged in the immediate aftermath of a particular event. The researcher had taken the photos purely out of interest, and they were not directly relevant to her current research or future plans. Notably, the researcher also holds an electronic collection of Kyrgyz newspapers that no longer exist and no longer have web archives.
FOOTNOTES
1 According to the analysis of Arnett (2008), 67 percent of American studies published during the year 2007 in the Journal of Personality and Social Psychology drew their research subjects from the pool of psychology undergraduates. For non-American studies the rate was even higher, 80 percent (Arnett 2008, 604). For a more extensive discussion and critique of this issue, see Henrich et al. (2010).